Par le
On voit passer beaucoup d’avis sur ChatGPT, mais finalement, qu’en sait-on ? Juste que c’est un réseau de neurones artificiels avec des milliards de paramètres, capable de tenir une discussion de haut niveau, mais aussi de tomber dans des pièges grossiers tendus par des internautes facétieux. On nous parle beaucoup de lui mais on en sait finalement très peu sur son fonctionnement.
Je vous propose donc de présenter les mécanismes principaux sur lesquels ChatGPT repose et de montrer ainsi que, si le résultat est parfois impressionnant, ses mécanismes élémentaires sont astucieux mais pas vraiment nouveaux. Pour ce faire, passons en revue les différents termes du sigle « ChatGPT ».
Un « transformer » est un réseau de neurones qui bénéficie du même algorithme d’apprentissage que les réseaux profonds (deep networks), qui a déjà fait ses preuves pour l’entraînement de grosses architectures. Il bénéficie également de deux caractéristiques éprouvées : d’une part, des techniques de « plongement lexical » pour coder les mots ; d’autre part, des techniques attentionnelles pour prendre en compte le fait que les mots sont séquentiels.
Ce second point est majeur pour interpréter le sens de chaque mot dans le contexte de la phrase entière. La technique proposée par les transformers privilégie une approche numérique et statistique, simple à calculer massivement et très efficace. Cette approche consiste à apprendre, pour chaque mot et à partir de l’observation de nombreux textes, à quels autres mots de la phrase il faut faire « attention » pour identifier le contexte qui peut modifier le sens de ce mot. Ceci permet d’accorder un mot ou de remplacer un pronom par les mots de la phrase qu’il représente.
ChatGPT est capable de générer du langage : on lui expose un problème et il nous répond avec du langage – c’est un « modèle de langage ».
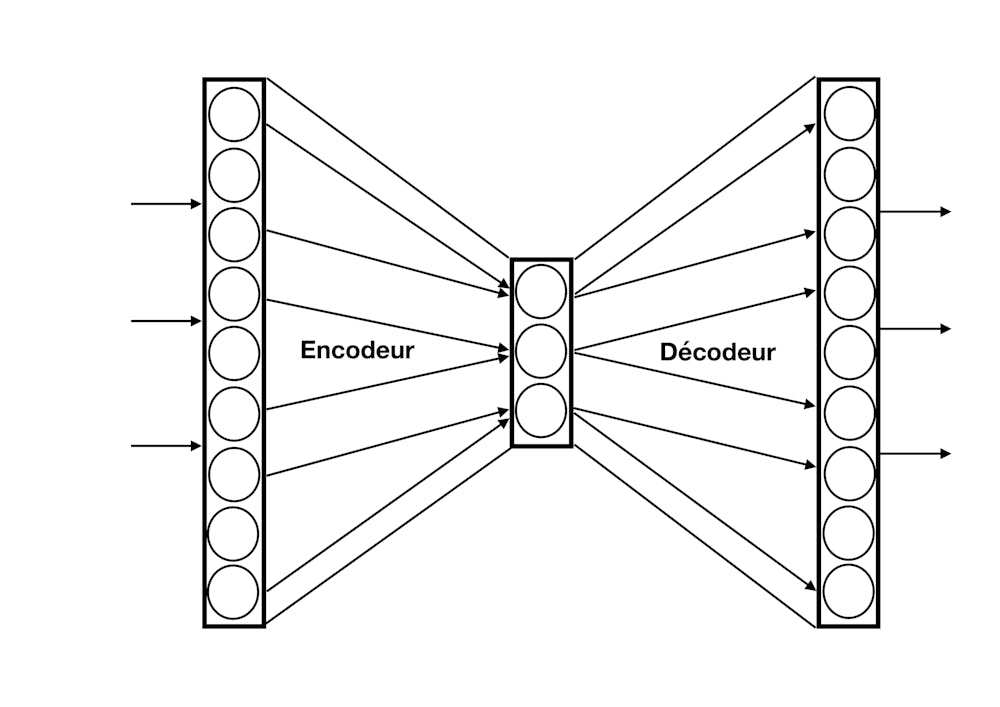
La possibilité d’apprendre un modèle génératif avec un réseau de neurones date de plus de trente ans : dans un modèle d’auto-encodeur, la sortie du réseau est entraînée pour reproduire le plus fidèlement possible son entrée (par exemple une image de visage), en passant par une couche de neurones intermédiaire, choisie de petite taille : si on peut reproduire l’entrée en passant par une représentation aussi compacte, c’est que les aspects les plus importants de cette entrée (le nez, les yeux) sont conservés dans le codage de cette couche intermédiaire (mais les détails doivent être négligés car il y a moins de place pour représenter l’information). Ils sont ensuite décodés pour reconstruire un visage similaire en sortie.
Utilisé en mode génératif, on choisit une activité au hasard pour la couche intermédiaire et on obtient en sortie, à travers le décodeur, quelque chose qui ressemblera à un visage avec un nez et des yeux mais qui sera un exemplaire inédit du phénomène considéré.
C’est par exemple en suivant ce procédé (avec des réseaux de grande taille) que l’on est capable de créer des deepfakes, c’est-à-dire des trucages très réalistes.
Si on souhaite maintenant générer des phénomènes séquentiels (des vidéos ou des phrases), il faut prendre en compte l’aspect séquentiel du flux d’entrée. Ceci peut être obtenu avec le mécanisme attentionnel décrit plus haut, utilisé sous une forme prédictive. En pratique, si l’on masque un mot ou si on cherche le mot suivant, on peut prédire ce mot manquant à partir de l’analyse statistique des autres textes. À titre d’illustration, voyez à quel point vous êtes capables de lire une BD des Schtroumpfs et de remplacer chaque « schtroumpf » par un mot issu de l’analyse attentionnelle des autres mots.
L’efficacité d’un simple mécanisme attentionnel (qui considère les autres mots importants du contexte mais pas explicitement leur ordre) pour traiter l’aspect séquentiel des entrées a été un constat majeur dans la mise au point des transformers (« Vous n’avez besoin que d’attention » titrait la publication correspondante : « Attention is all you need »), car auparavant les méthodes privilégiées utilisaient des réseaux plus complexes, dits récurrents, dont l’apprentissage est comparativement bien plus lent et moins efficace ; de plus ce mécanisme attentionnel se parallélise très bien, ce qui accélère d’autant plus cette approche.
L’efficacité des transformers n’est pas seulement due à la puissance de ces méthodes, mais aussi (et surtout) à la taille des réseaux et des connaissances qu’ils ingurgitent pour s’entrainer.
Les détails chiffrés sont difficiles à obtenir, mais on entend parler pour des transformers de milliards de paramètres (de poids dans les réseaux de neurones) ; pour être plus efficaces, plusieurs mécanismes attentionnels (jusqu’à cent) sont construits en parallèle pour mieux explorer les possibles (on parle d’attention « multi-tête »), on peut avoir une succession d’une dizaine d’encodeurs et de décodeurs, etc.
Rappelons que l’algorithme d’apprentissage des deep networks est générique et s’applique quelle que soit la profondeur (et la largeur) des réseaux ; il suffit juste d’avoir assez d’exemples pour entraîner tous ces poids, ce qui renvoie à une autre caractéristique démesurée de ces réseaux : la quantité de données utilisée dans la phase d’apprentissage.
Ici aussi, peu d’informations officielles, mais il semble que des pans entiers d’internet soient aspirés pour participer à l’entrainement de ces modèles de langages, en particulier l’ensemble de Wikipedia, les quelques millions de livres que l’on trouve sur Internet (dont des versions traduites par des humains sont très utiles pour préparer des transformers de traduction), mais aussi très probablement les textes que l’on peut trouver sur nos réseaux sociaux favoris.
Cet entrainement massif se déroule hors ligne, peut durer des semaines et utiliser des ressources calculatoires et énergétiques démesurées (chiffrées à plusieurs millions de dollars, sans parler des aspects environnementaux d’émission de CO?, associés à ces calculs).
Nous sommes maintenant en meilleure position pour présenter ChatGPT : il s’agit d’un agent conversationnel, bâti sur un modèle de langage qui est un transformer génératif pré-entraîné (GPT).
Les analyses statistiques (avec approches attentionnelles) des très grands corpus utilisés permettent de créer des séquences de mots ayant une syntaxe de très bonne qualité. Les techniques de plongement lexical offrent des propriétés de proximité sémantique qui donnent des phrases dont le sens est souvent satisfaisant.
Outre cette capacité à savoir générer du langage de bonne qualité, un agent conversationnel doit aussi savoir converser, c’est-à-dire analyser les questions qu’on lui pose et y apporter des réponses pertinentes (ou détecter les pièges pour les éviter). C’est ce qui a été entrepris par une autre phase d’apprentissage hors-ligne, avec un modèle appelé « InstructGPT », qui a nécessité la participation d’humains qui jouaient à faire l’agent conversationnel ou à pointer des sujets à éviter. Il s’agit dans ce cas d’un « apprentissage par renforcement » : celui-ci permet de sélectionner des réponses selon les valeurs qu’on leur donne ; c’est une sorte de semi-supervision où les humains disent ce qu’ils auraient aimé entendre (ou pas).
Les caractéristiques énoncées ici permettent de comprendre que la principale fonction de ChatGPT est de prédire le mot suivant le plus probable à partir des nombreux textes qu’il a déjà vus et, parmi les différentes suites probables, de sélectionner celles qu’en général les humains préfèrent.
Cette suite de traitements peut comporter des approximations, quand on évalue des statistiques ou dans les phases de décodage du modèle génératif quand on construit de nouveaux exemples.
Ceci explique aussi des phénomènes d’hallucinations rapportées, quand on lui demande la biographie de quelqu’un ou des détails sur une entreprise et qu’il invente des chiffres et des faits. Ce qu’on lui a appris à faire c’est de construire des phrases plausibles et cohérentes, pas des phrases véridiques. Ce n’est pas la peine de comprendre un sujet pour savoir en parler avec éloquence, sans donner forcément de garantie sur la qualité de ses réponses (mais des humains aussi savent faire ça…).
Frédéric Alexandre, Directeur de recherche en neurosciences computationnelles, Université de Bordeaux, Inria
Cet article est republié à partir de The Conversation sous licence Creative Commons. Lire l’article original.
Par le
Nos données personnelles sont partout sur internet, et peuvent être utilisées à très mauvais escient. ??????? ?????????-????????? , Unsplash, CC BY
Nos données personnelles circulent sur Internet : nom, adresses, coordonnées bancaires ou de sécurité sociale, localisation en temps réel… et les affaires qui y sont liées se font une place pérenne dans le débat public, du scandale Facebook-Cambridge Analytica au vol de données à la Croix-Rouge, en passant par les récents blocages d’hôpitaux par des rançongiciels (ou ransomware) et l’interdiction de l’application TikTok pour les fonctionnaires de plusieurs pays.
Mais si l’on sait de plus en plus que nos données personnelles sont « précieuses » et offrent des possibilités sans précédent en matière de commercialisation et d’innovation, il est parfois difficile de saisir ou d’expliquer pourquoi il faudrait les protéger.
Le premier risque concerne la perte du contrôle sur nos propres données. C’est ce qui arrive par exemple quand on autorise le traçage par des sites ou des applications : on autorise l’enregistrement de nos activités sur le Web ou sur notre smartphone (pages visitées, géolocalisation) et l’échange de ces données, et, une fois cet accord donné, nous n’avons plus aucun pouvoir sur la circulation de nos données.
Ces informations sont utilisées le plus souvent pour du profilage qui permet d’alimenter l’économie de la publicité personnalisée régie dorénavant par des plates-formes d’enchères valorisant les données relatives aux profils utilisateurs contre des emplacements publicitaires.
Mais, ces informations peuvent également être utilisées à mauvais escient. La connaissance de votre localisation peut aider le passage à l’acte d’un cambrioleur par exemple, et la connaissance de vos centres d’intérêts ou opinion politique peut vous exposer à des opérations d’influence.
Le scandale Cambridge Analytica en est un exemple, avec l’exploitation de données personnelles de millions d’utilisateurs Facebook pour des campagnes de désinformation ciblées afin d’influencer des intentions de vote. Plus récemment, les révélations du Monde sur les entreprises de désinformation indiquent que cette pratique n’est pas un cas isolé.
Un autre risque concerne l’hameçonnage : si des informations personnelles sont présentes dans un courriel ou SMS frauduleux, il vous paraîtra plus réaliste et abaissera vos barrières de vigilance. L’hameçonnage sert souvent à infecter la cible avec un rançongiciel (ransomware en anglais) : les cybercriminels utilisent des informations personnalisées pour gagner la confiance des destinataires et les inciter à ouvrir des pièces jointes, ou à cliquer sur des liens ou documents malveillants, ce qui permet dans un second temps de verrouiller les données de la victime et d’en interdire l’accès. Une rançon est ensuite réclamée pour les déverrouiller.
[Près de 80 000 lecteurs font confiance à la newsletter de The Conversation pour mieux comprendre les grands enjeux du monde. Abonnez-vous aujourd’hui]
Bien que les attaques par rançongiciel les plus médiatisées concernent des organisations, des hôpitaux par exemple, les particuliers sont également touchés.
Dans le cas de l’usurpation d’identité, une personne malveillante utilise des informations personnelles qui permettent de nous identifier (« se logger ») sans notre accord : par exemple, en créant un faux profil sur une plate-forme et en rédigeant des commentaires sous l’identité de la victime afin de nuire à sa réputation.
À un autre niveau, la surveillance de masse exercée par certains États capture les informations personnelles de leurs citoyens afin d’entraver la liberté d’expression ou de ficher les individus par exemple. Une surveillance accrue peut tendre vers un sentiment d’absence de sphère privée et ainsi brider le comportement des individus.
En Europe, le RGPD (règlement général sur la protection des données) limite la récolte des données personnelles, notamment par les gouvernements, qui doivent justifier d’une raison suffisante pour toute surveillance.
Ces problèmes touchent chacun d’entre nous. En effet, dans un monde de plus en plus numérique où nous générons quotidiennement des données à travers notre navigation sur Internet, nos smartphones, ou nos montres connectées, nous avons tous une « empreinte numérique unique ».
En clair, il est généralement possible de réidentifier quelqu’un juste à partir des « traces » que nous laissons derrière nous sur nos appareils numériques.
Par exemple, l’observation aléatoire de quatre lieux visités seulement représente une signature unique pour 98 % des individus. Cette unicité est généralisable dans un grand nombre de comportements humains.
Cacher l’identité du propriétaire de données personnelles uniquement derrière un pseudonyme n’est pas une protection suffisante face au risque de réidentification, il est nécessaire d’anonymiser les données.
Tels les membres d’un « black bloc » essayant d’être indistinguables entre eux en s’habillant de manière identique dans une manifestation houleuse, l’anonymisation de données a pour but d’éviter qu’une personne ne se démarque du reste de la population considérée, afin de limiter l’information qu’un cyberattaquant pourrait extraire.
Dans le cas de données de géolocalisation, on pourrait par exemple modifier les données afin que plusieurs utilisateurs partagent les mêmes lieux visités, ou alors introduire du bruit pour ajouter une incertitude sur les lieux réellement visités.
Mais cette anonymisation a un coût car elle « déforme » les données et diminue leur valeur : une trop grande modification des données brutes dénature l’information véhiculée dans les données anonymisées. De plus, pour s’assurer de l’absence d’une empreinte réidentifiante, les modifications nécessaires sont très importantes et souvent incompatibles avec nombre d’applications.
Trouver le bon compromis entre protection et utilité des informations anonymisées reste un challenge. À l’heure où certains voient les données comme le nouveau pétrole du XXIe siècle, l’enjeu est de taille car une donnée anonyme n’est plus considérée comme une donnée personnelle et échappe au RGPD, ce qui veut dire qu’elle peut être partagée sans consentement du propriétaire.
Cette difficulté de trouver un compromis acceptable entre protection et utilité des données au travers de mécanismes d’anonymisation a fait évoluer les pratiques. De nouveaux paradigmes de protection des données personnelles ont vu le jour.
Une première tendance consiste à générer des données synthétiques reproduisant les mêmes propriétés statistiques que les vraies données.
Ces données générées de manière artificielle ne sont par conséquent pas liées à une personne et ne seraient plus encadrées par le RGPD. Un grand nombre d’entreprises voient en cette solution des promesses de partage d’information moins limitées. En pratique, les risques résiduels des modèles de génération synthétique ne sont pas négligeables et sont encore à l’étude.
Une autre solution limitant le risque de partage de données personnelles est l’apprentissage fédéré. Dans l’apprentissage machine conventionnel, les données sont centralisées par une entité pour entraîner un modèle.
Dans l’apprentissage fédéré, chaque utilisateur se voit attribuer un modèle qu’il entraîne localement sur ses propres données. Il envoie ensuite le résultat à une entité qui s’occupe d’agréger l’ensemble des modèles locaux. De manière itérative, cet apprentissage décentralisé permet de créer un modèle d’apprentissage sans divulguer de données personnelles.
Ce nouveau paradigme de protection des données personnelles suscite beaucoup d’engouement. Cependant, plusieurs limitations subsistent, notamment sur la robustesse face aux acteurs malveillants qui souhaiteraient influencer le processus d’entraînement. Un participant pourrait par exemple modifier ses propres données pour que le modèle se trompe lors d’une tâche de classification particulière.
Antoine Boutet, Maitre de conférence, Privacy, IA, au laboratoire CITI, Inria, INSA Lyon – Université de Lyon
Cet article est republié à partir de The Conversation sous licence Creative Commons. Lire l’article original.
Par le
TikTok est largement en tête des applications les plus utilisées par les jeunes du monde entier. Ti Via/Shutterstock
TikTok est une application de médias sociaux, propriété de l’entreprise chinoise ByteDance. Le principe de TikTok, née en septembre 2016 sous le nom de Douyin (nom qu’elle a conservé à ce jour en Chine) repose sur le partage de courtes vidéos. Elle définit sa mission de façon très sympathique : « TikTok est la meilleure destination pour les vidéos mobiles au format court. Notre mission est d’inspirer la créativité et d’apporter la joie. »
Aujourd’hui, du fait des récentes révélations sur son fonctionnement exact, elle inspire plutôt l’inquiétude : les États-Unis et l’UE ont déjà interdit à leurs fonctionnaires de s’en servir, et d’autres mesures pourraient suivre.
Il faut garder à l’esprit que, comme toute entreprise chinoise, TikTok, apparue sur les smartphones des habitants des pays occidentaux en 2017, est tenue de servir les intérêts de la Chine et de répondre aux desiderata gouvernementaux.
Si l’usage de TikTok est illimité pour les utilisateurs étrangers, en Chine, Douyin, sa version chinoise, est limitée à quarante minutes par jour pour les moins de quatorze ans. Cela n’est pas anodin. Nous y reviendrons.
Autre particularité : c’est le gouvernement chinois qui décide des contenus qui seront mis en avant. Certains contenus sont pour le moins troublants et ciblent un public très jeune : en décembre 2022, le Centre de lutte contre la haine en ligne (CCDH), a démontré dans une étude que « l’algorithme du réseau social TikTok favorise la diffusion de contenus relatifs aux troubles alimentaires et à l’automutilation pour certains comptes ». Et ce, en fonction des publications vues et « likées » par les utilisateurs cherchant des contenus relatifs à « l’image de soi et à la santé mentale ». Est-ce le fait d’une modération insuffisante de la plate-forme au regard de ses règles ? La question peut se poser !
[Près de 80 000 lecteurs font confiance à la newsletter de The Conversation pour mieux comprendre les grands enjeux du monde. Abonnez-vous aujourd’hui]
Dans un tout autre domaine, la guerre en Ukraine, la propagande des mercenaires russes de Wagner sur TikTok et la désinformation afférente ont été récemment dénoncées dans un rapport de NewsGuard. Ici encore, au regard du positionnement du gouvernement chinois dans ce conflit, la question d’une véritable volonté de modération peut se poser.
Comme le pointe Fabrice Ebelpoin, entrepreneur, professeur à Sciences Po et spécialiste des réseaux sociaux, autant la version chinoise propose massivement à ses utilisateurs « des vidéos sur le sens de la nation, l’unité, l’ambition personnelle mise au service du collectif, tout un tas de valeurs qui font la spécificité chinoise », autant aux États-Unis comme en Europe, « la plate-forme est dédiée exclusivement à de l’entertainment niais ou alors des choses qui peuvent prêter à confusion ». Et le professeur d’ajouter : « On est sur quelque chose qui peut s’apparenter à une destruction de l’état d’esprit de la jeunesse occidentale. »
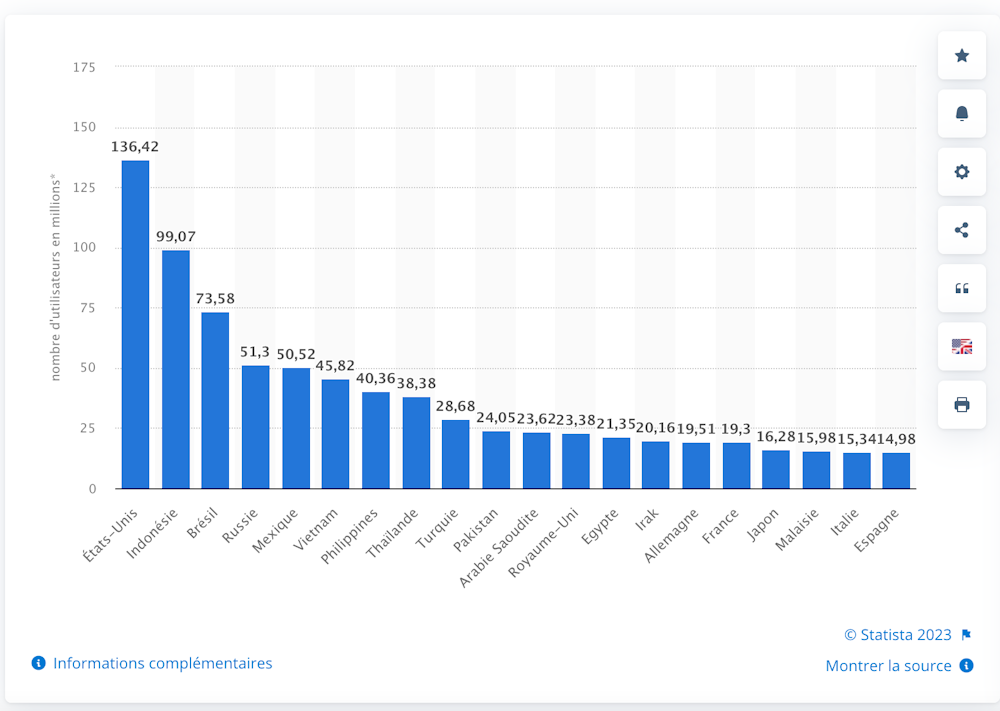
En 2022, TikTok comptait pas moins de 1,7 milliard d’utilisateurs actifs dans le monde.
En termes de confidentialité, si TikTok, comme d’autres réseaux sociaux, a accès à de nombreuses informations « traditionnelles » des utilisateurs – navigations, visionnages, conversations, listes de contacts, localisation, accès à leur appareil photo et au micro du mobile –, l’entreprise a précisé, dans la mise à jour de sa politique de confidentialité, que les données des utilisateurs français (entre autres) étaient accessibles aux employés de la plate-forme. C’est ce qu’a indiqué dans un billet de blog publié le 2 novembre 2022, Elaine Fox, « Head of Privacy Europe » pour la firme.
Nous l’avons évoqué : aux États-Unis, depuis décembre 2022 le réseau social est banni des téléphones professionnels des membres la Chambre des représentants et des agences fédérales. Dans la même dynamique, le 23 février 2023, la Commission européenne a annoncé l’interdiction d’installer l’application sur tous les appareils professionnels de son personnel. Le 27 février, c’était au tour de la présidente du Conseil du Trésor canadien Monat Fortier d’annoncer
Dans certains pays, ce sont les usages de TikTok qui, selon les lois locales, peuvent amener des utilisateurs devant les tribunaux. Exemples parmi d’autres : en 2022 une Égyptienne se voyait condamnée à trois ans de prison pour ses vidéos sur TikTok. En février 2023, un couple iranien a été condamné à 10 ans de prison pour une vidéo de danse devenue virale.
La France, où le réseau social fait l’objet d’une commission d’enquête au Sénat qui devrait bientôt rendre un rapport sur son fonctionnement, qualifié d’« addictif et d’opaque », ne fait pas exception : un influenceur a été condamné après sa vidéo de danse en crop top dans une église. D’autres pays restreignent l’usage de TikTok, jusqu’à des décisions plus radicales : l’application est ainsi interdite en Inde, au Pakistan ou encore en Afghanistan, et avait été interdite un temps au Bangladesh et en Indonésie… qui jugeaient le contenu diffusé « inapproprié et blasphématoire », le temps que TikTok revienne avec une version hautement censurée.
Par ailleurs il existe de nombreux moyens de contourner les interdictions et les blocages : en Inde, deux ans apres l’interdiction gouvernementale de la plate-forme chinoise en juin 2020, les applications « copy-cat » se sont multipliées : citons Josh, Chingari, MX TakaTak…
Certes, les risques de piratage existent, et des mises à jour peuvent intégrer des failles de sécurité volontaires, comme un programme backdoor. Toutefois, il convient à ce stade de faire plusieurs remarques.
Nous pouvons raisonnablement nous interroger sur le caractère symbolique des décisions des administrations occidentales évoquées ci-dessus. D’une part, les fonctionnaires concernés possèdent des téléphones personnels – à moins qu’ils n’en soient dépossédés lorsqu’ils accèdent à ces institutions – et des échanges sensibles peuvent être effectués via ces téléphones privés. Donc, à première vue, un piratage massif à ciel ouvert pouvant bénéficier de l’aide des utilisateurs pourrait être possible lors d’une mise à jour, et rendre ces derniers complices de leur propre espionnage !
La ficelle semble un peu grossière. Les services de renseignements disposent probablement d’autres méthodes, et la véritable prudence dans les domaines sensibles va au-delà de la vigilance à l’égard d’une simple application pouvant potentiellement être utilisée à des fins d’espionnage.
Quand on connaît, par exemple, le [potentiel de Pegasus], un puissant logiciel espion commercialisé par la société israélienne NSO, et qui était utilisé en 2022 par pas moins de 22 services de sécurité dans douze pays européens, l’intérêt premier de TikTok pour la Chine semble se situer ailleurs… et le gouvernement chinois paraît être intéressé par d’autres potentialités de l’application, à savoir celles liées à sa couverture mondiale démesurée. Par ailleurs les smartphones sont déjà en soi des outils d’espionnage de leurs utilisateurs, ce n’est pas une application, quelle qu’elle soit, qui change la donne.
Les statistiques concernant les usagers en 2023 dans le monde sont les suivantes :
56 % sont des femmes, 44 % des hommes.
51,3 % de l’audience sont des femmes entre 13 et 24 ans.
23,6 % des utilisateurs sont âgés entre 13 et 24 ans.
40 % des visiteurs quotidiens se situent dans la tranche 15-24 ans.
Les chiffres relevés par l’étude annuelle de Qustodio – un fournisseur de logiciels de contrôle parental – indiquent qu’en 2022, dans le monde, les enfants (4-18 ans) ont passé en moyenne près de deux heures par jour sur TikTok (1h47).
Par-delà les contenus qui peuvent s’avérer inappropriés – sans l’activation et le paramétrage d’une fonctionnalité mise en place par TikTok en 2020 sous le nom de « Family Pairing », qui permet aux parents d’avoir le contrôle sur les activités de leurs enfants –, un autre risque pernicieux existe, qui semble plus réaliste que les piratages de données évoqués par les institutions précitées, un risque qui concerne une population majoritairement jeune au travers de campagnes de manipulation des opinions publiques. Une sorte de « brain-hacking » déclenchable à l’envi…
Le 2 décembre 2022, le directeur du FBI, Chris Wray, se préoccupait ainsi des possibilités offertes au gouvernement chinois de « manipuler le contenu et, s’ils le souhaitent, de l’utiliser pour des opérations d’influence », c’est-à-dire d’engager des campagnes d’astroturfing à très grande échelle.
Dans l’attente d’un réseau de substitution qui serait, lui, maîtrisé, l’Europe prépare peut-être son opinion publique à une interdiction pure et simple – une interdiction que Donald Trump appelait de ses vœux en 2020 pour les États-Unis. Par les mesures prises dernièrement, les Occidentaux adressent de façon concomitante au gouvernement chinois une exigence pour ne pas arriver à une telle issue : l’abrogation du contrôle par Pékin des contenus mis en avant. Une exigence qui s’apparente à un vœu pieux. C’était là, d’ailleurs ce qui expliquait la volonté de Donald Trump de contraindre TikTok à se faire racheter aux États-Unis par les groupes américains Oracle et Walmart, projet auquel Washington à finalement renoncé. Ce qui est plus réaliste, c’est un stockage de données respectueux de la souveraineté numérique des États de l’UE. Mais que les usagers se rassurent : Cormac Keenan, Head of Trust and Safety, chez TikTok le promet : la lutte contre la désinformation est une priorité de la firme !
Yannick Chatelain, Professeur Associé. Digital I IT. GEMinsights Content Manager, Grenoble École de Management (GEM)
Cet article est republié à partir de The Conversation sous licence Creative Commons. Lire l’article original.
Par le
Les influenceurs ont largement investi la sphère digitale depuis ces dix dernières années. Avec l’essor des réseaux sociaux numériques tels que TikTok, YouTube ou bien encore Instagram, ils ont acquis de larges audiences, de quelques milliers à plusieurs millions d’internautes pour certains d’entre eux, devant lesquelles ils partagent leurs passions, style de vie ou encore bons plans et astuces.
Si leur pouvoir d’influence est incontestable, leurs recommandations sont aujourd’hui de plus en plus remises en cause. À la frontière entre conseil amical et publicité, les pratiques d’une partie des influenceurs restent floues, ambiguës, voire trompeuses. Des scandales ont notamment éclaté concernant des « dropshipping » abusifs (achat de produits sur des sites pour les revendre plus cher sur son propre magasin en ligne), des recommandations vantant les mérites d’un produit jamais testé ni même acheté ou encore de la promotion d’arnaques.
Alors qu’en France, les victimes d’influenceurs s’organisent à travers le collectif AVI, la résistance des internautes s’organise également via les réseaux sociaux : c’est la désinfluence.
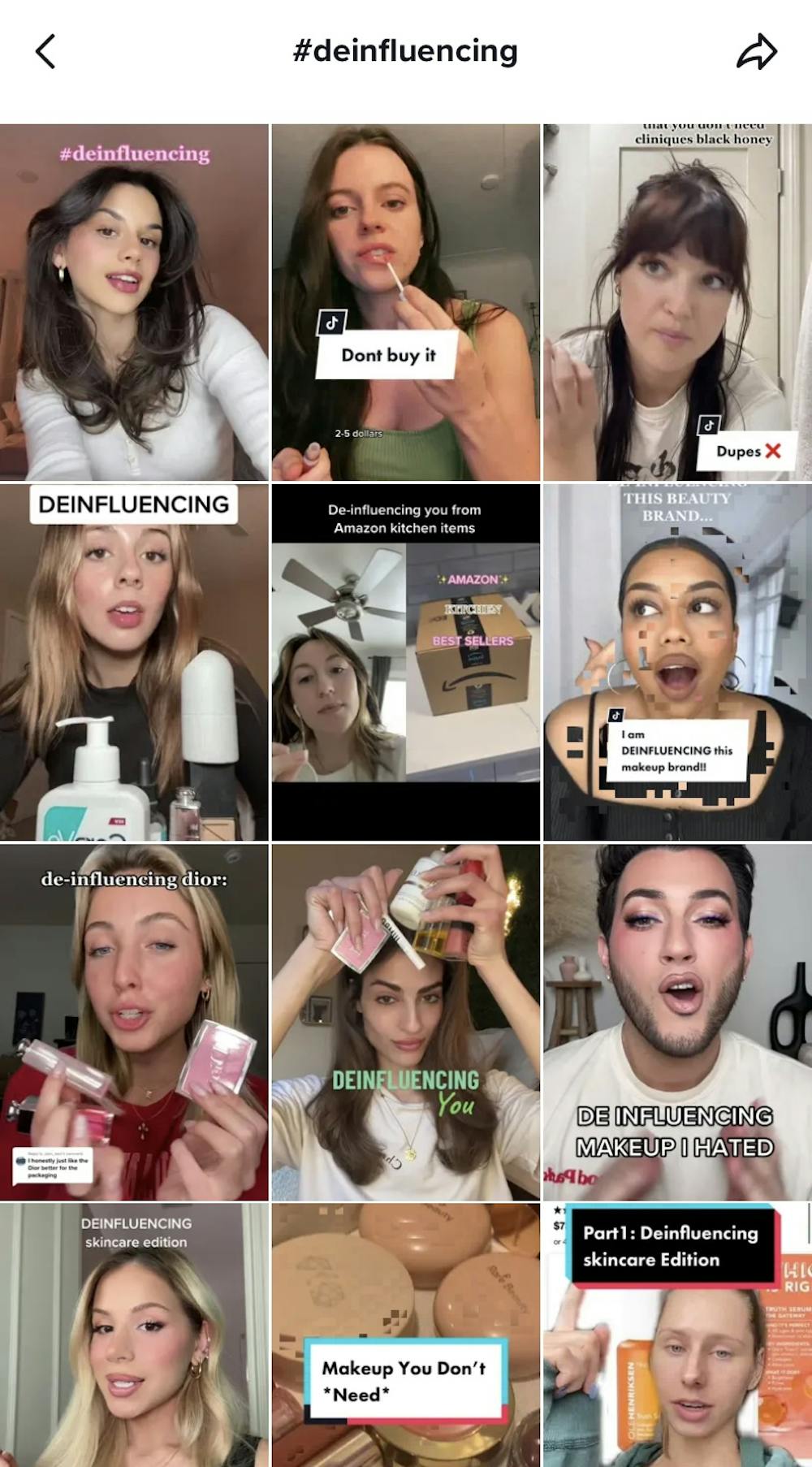
Le hashtag #deinfluencing accumule aujourd’hui plus de 277 millions de vues sur TikTok (réseau social où cette tendance est apparue). La « désinfluence » (« deinfluencing » en anglais) constitue la dernière tendance digitale de résistance à la surconsommation.
Elle renvoie à une prise de parole des internautes qui questionnent leur rapport à l’influence et à la surconsommation et qui dénoncent des pratiques d’influence peu éthiques, voire fallacieuses. Alors que les réseaux sociaux ont permis aux influenceurs (et aux marques) de produire un flot incessant de recommandations, leur impact économique et environnemental est questionné.
Les contenus produits avec ce hashtag peuvent prendre la forme de listes de produits « tendance » sur la plate-forme qu’ils n’achèteront pas (« things you cannot convince me to buy ») ou encore le partage d’expériences négatives de consommation visant à convaincre de ne pas acheter ces produits.
Pour l’instant très viral sur TikTok, notamment à l’encontre de certains influenceurs beauté, ce mouvement pourrait s’étendre vers d’autres réseaux sociaux et d’autres domaines face à des influenceurs parfois peu regardants sur les produits qu’ils recommandent.
La recherche académique permet de mieux comprendre ce mouvement de défense des consommateurs contre les tentatives de persuasion existantes sur les réseaux sociaux. De nombreuses théories sociologiques et marketing traitant de la création virtuelle de liens sociaux et de pratiques publicitaires éclairent ce phénomène.
[Près de 80 000 lecteurs font confiance à la newsletter de The Conversation pour mieux comprendre les grands enjeux du monde. Abonnez-vous aujourd’hui]
Tout d’abord, les influenceurs créent une relation « para-sociale » avec leurs abonnés. Cette relation est développée à distance avec un personnage médiatique. Bien qu’unilatérale, elle se fonde sur le sentiment d’intimité et un lien psychologique affectif. Le public croit et comprend le personnage médiatique. Une telle relation peut se développer avec des personnages de séries télévisées, des artistes et… des producteurs de contenu.
Plusieurs recherches ont mis en avant qu’une relation parasociale constituait un vecteur puissant de l’intention d’achat sur les réseaux sociaux. Les professionnels du marketing ayant fait le même constat, les influenceurs sont devenus un outil de publicité très populaire. Le marketing de l’influence représente une industrie dépassant les 16 milliards de dollars en 2022.
Cette collaboration entre marques et influenceurs peut prendre de multiples formes, comme des envois de produits gratuits, des vidéos sponsorisées, des voyages luxueux… Et elle ne passe pas inaperçue aux yeux des consommateurs.
Cette remise en question de l’activité des influenceurs découle d’une perte de confiance des consommateurs, ainsi qu’à un environnement économique et écologique qui semble plus fragile et qui invite à la remise en question. Les consommateurs participant au mouvement #deinfluencing s’inscrivent dans une forme de rejet du contenu publicitaire déguisé, souvent très éloigné des valeurs actuelles de durabilité.
Cette perte de confiance peut provenir de déceptions à la suite d’achat de produits, de l’accroissement des contenus rémunérés ou encore de l’apparition de pratiques abusives. Ainsi, la sponsorisation est source de méfiance de la part des consommateurs, car il devient difficile de faire confiance au jugement d’un influenceur lorsque celui-ci est rémunéré par la marque. Le manque de transparence crée un sentiment de défiance, voire un sentiment de trahison.
Nous pouvons prendre l’exemple récent de Mikayla Noguiera, maquilleuse et star américaine des réseaux sociaux, qui a fait scandale en faisant un placement de produit pour un mascara L’Oréal considéré comme mensonger par les internautes (ceux-ci la soupçonnant d’avoir utilisé de faux cils). Les rumeurs d’escroquerie et d’abus de confiance se développent également en France, ce qui participe d’autant plus à cette remise en question de la crédibilité des influenceurs.
Au-delà de ce problème de confiance dans la performance des produits conseillés par les influenceurs, ceux-ci, en se professionnalisant, développent un style de vie de plus en plus éloigné de celui de leurs followers. Ils perdent en proximité avec eux et ne représentent plus le consommateur. Leur statut se rapproche alors d’un ambassadeur de marque, peu connecté aux problématiques réelles de leurs abonnés.
Dernièrement, la marque de cosmétiques Tarte a organisé un voyage très luxueux pour un groupe d’influenceurs, afin de promouvoir un lancement de produit. Ce voyage a été décrié par les internautes qui y ont vu un manque de sensibilité de la marque aux questions écologiques et à la situation économique actuelle (les influenceurs ayant été envoyés à Dubaï par avion en classe business puis logés dans un hôtel luxueux).
Cette tendance à la désinfluence vise donc à rompre le discours positif d’influenceurs sur certains produits, en le remplaçant par un contre-discours de consommateurs ordinaires soumis à des contraintes plus proches de la majorité des consommateurs (budgétaires, de limitation d’espace de stockage, de prise en compte de l’écologie, etc.).
Mieux éduqués, les consommateurs développent une conscience croissante des différentes tentatives de persuasion auxquelles ils sont soumis. Lorsqu’ils perçoivent une tentative de persuasion, ils vont développer des stratégies afin d’y échapper (zapping des publicités télévisuelles ; changement de radio pendant la coupure publicitaire, etc.). Or l’influence digitale reste un outil relativement nouveau à l’échelle de l’histoire des pratiques publicitaires, car il est lié au développement des réseaux sociaux. La connaissance des consommateurs et donc leurs pratiques d’évitement sont ainsi encore au stade de développement.
Ceci fait alors écho à d’autres phénomènes de résistance des consommateurs tels que le boycott, les techniques d’évitement de la publicité (ad blockers, zapping…), les mouvements anticonsuméristes (ou minimalistes) ou encore le téléchargement illégal.
Face au deinfluencing, deux axes sont envisageables pour les marques : recréer de la confiance et se rapprocher des problématiques des consommateurs. Ceci se fondera d’une part sur une transparence irréprochable de la part des influenceurs mais également sur un cadre législatif plus clair qui viendra protéger les consommateurs des abus.
Le contenu même des influenceurs est appelé à s’adapter en incitant moins à la surconsommation non réfléchie, en faisant des analyses plus complètes (basées sur un essai-produit réalisé sur une longue période, montrant différents modes d’utilisation d’un même produit, contextualisant la performance du produit…) ou encore en promouvant des achats plus durables et limitant le gaspillage.
Camille Lacan, Maître de Conférences en Sciences de Gestion et du Management, IAE de Perpignan, Université de Perpignan et Alice Crépin, Professeure assistante en marketing, ESSCA École de Management
Cet article est republié à partir de The Conversation sous licence Creative Commons. Lire l’article original.
{kind=link}
{kind=link}
{kind=link}
{kind=link}